L’expertise de l’ENSAI au service des Learning Analytics
L’ENSAI est un des dix établissements d’enseignement supérieur rennais investis dans le projet d’innovation pédagogique DUNE-DESIR. Au sein du pôle Data Tank, la grande école de la Data Science met son savoir-faire au service des Learning Analytics.
Zoom sur VisLinguistique, un outil de visualisation du niveau de langue anglaise d’étudiants. Anas Knefati, ingénieur de recherche, en a exploité et valorisé les données.
Learning Analytics, une définition
Les Learning Analytics ou analyse de l’apprentissage, sont la “mesure, la collecte, l’analyse et la présentation de rapports basés sur des données des apprenants en contexte d’apprentissage dans le but de comprendre et d’optimiser l’apprentissage et le contexte”, selon la définition proposée lors de la Conférence Learning Analytics & Knowledge en 2011.
Le suivi des progrès des apprenants ou encore l’analyse des données collectées à des fins d’amélioration de l’apprentissage et de l’enseignement ont toujours eu cours. Les Learning Analytics, en plein essor, se distinguent par le fait qu’elles enrichissent ces disciplines de techniques d’analyse issues de la data science.
Les Learning Analytics sont au cœur du projet DUNE-DESIR et plus spécifiquement de son pôle Data Tank.
DUNE-DESIR : objectif innovation pédagogique
Le projet DESIR « Développement d’un Enseignement Supérieur Innovant à Rennes » est issu d’une collaboration entre l’Université Rennes 2, l’Université de Rennes 1 et huit grandes écoles publiques de Rennes, parmi lesquelles l’ENSAI. DESIR est lauréat 2016 de l’appel à projets DUNE “Développement d’universités numériques expérimentales”.
L‘objectif du projet : “favoriser la transformation des pratiques pédagogiques universitaires afin de renforcer la réussite des étudiants de licence par l’innovation pédagogique et numérique soutenue par la recherche en éducation et e-éducation”.
DUNE-DESIR est structuré autour de trois entités ; la Maison de la Pédagogie, le Pôle d’ingénierie pédagogique ; Data Tank, le pôle d’analyse de données d’apprentissage et de modélisation et enfin le pôle de recherche coopérative¹.
Le Data Tank exploite et valorise les données d’apprentissage
Le Data Tank réunit des compétences en Data Science : modélisation statistique, machine learning, text mining, big data et système d’information des différents établissements universitaires et écoles partenaires du projet.
L’expertise en data science de l’ENSAI en fait un des acteurs principaux du Data Tank.
Ce pilier de DUNE-DESIR est une “ressource auprès des partenaires impliqués pour proposer des méthodologies et des outils, permettant l’exploitation et la valorisation des données d’enseignement et d’apprentissage. Le but est de promouvoir l’innovation pédagogique et numérique et de contribuer à la réussite des étudiants.
Le pôle fonctionne en mode projet. Il base son action sur une sélection de projets avec des besoins spécifiques en analyse de données.
Des actions sont proposées par le Data Tank aux porteurs de projet, qui peuvent compléter le travail de formalisation conceptuelle et d’observation de terrain du Living Lab, en appui des forces pédagogiques rendues disponibles par la Maison de la Pédagogie” ².
Au sein de l’ENSAI, Laurent Tardif, Brigitte Gelein et Anas Knefati sont membres du Data Tank et occupent les fonctions respectives de directeur, personne-ressource et ingénieur de recherche en Data Science.
Le savoir-faire de l’ENSAI au cœur du projet de Learning Analytics “VisLinguistique”
Le projet VisLinguistique est piloté par Thomas Gaillat, Maître de Conférence en linguistique et chercheur à l’EA Linguistique et Didactique des Langues (LIDILE) de l’Université Rennes 2.
Anas Knefati, ingénieur de recherche accueilli à l’ENSAI et Antoine Lafontaine, Data Scientist au sein du Data Tank, accueilli au Suptice de Rennes 1, présentent le projet :
“L’objectif est de créer un outil de visualisation des profils sémantiques et syntaxiques de texte saisis par les étudiants et d’évaluer l’impact de l’utilisation du dispositif sur l’évolution des compétences rédactionnelles en anglais des étudiants.
Une collecte de 269 écrits d’anciens apprenants (de niveau L2 à M1) avait été réalisée dans un premier temps afin de constituer un jeu de données étalon. […]
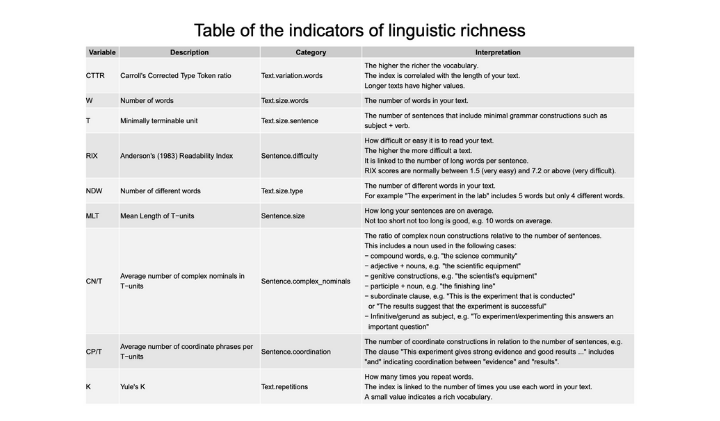
Les indicateurs de richesse linguistique utilisés dans le projet VisLinguistique
Ces données textuelles ont été par la suite concaténées et enrichies par annotation manuelle (avec la collaboration d’enseignants de langue du SCELVA de Rennes 1) (niveaux de langue CECRL) et automatique avant d’être formatées pour calculer des indicateurs de richesse linguistique. D’autres étudiants pourront alors par la suite visualiser leur profil linguistique et se positionner par rapport à l’échantillon étalon. […]
Le Data Tank s’est mis d’accord avec le porteur de projet pour participer dans un premier temps à l’enrichissement de scripts de deux langages différents (R et Python) déjà existants et à la construction d’une chaîne de traitement pour calculer les indicateurs de richesse linguistique. Le script Python fait appel au parseur (programme informatique d’analyse syntaxique) de l’Université de Stanford écrit en Java”. […]
Au sein du Data Tank, Anas Knefati et Antoine Lafontaine se chargent aussi de la visualisation des résultats, les étudiants pourront ainsi se positionner par rapport à d’autres étudiants français. Ils participent également à l’évaluation du dispositif, aux côtés de Laurent Tardif, directeur du Data Tank.
“L’utilisation d’un langage unique étant bénéfique à la construction de la chaîne de traitement, le script Python existant a été retranscrit en R et enrichi par la suite. Les scripts étaient initialement spécifiques pour un fonctionnement sous Linux. Une adaptation a aussi permis un fonctionnement de ces scripts sous Windows. Cette chaine fournit une base de données contenant les différents indicateurs syntaxiques de chaque étudiant. Elle fournit aussi autant de feedbacks (sous forme de rapports) que d’étudiants.
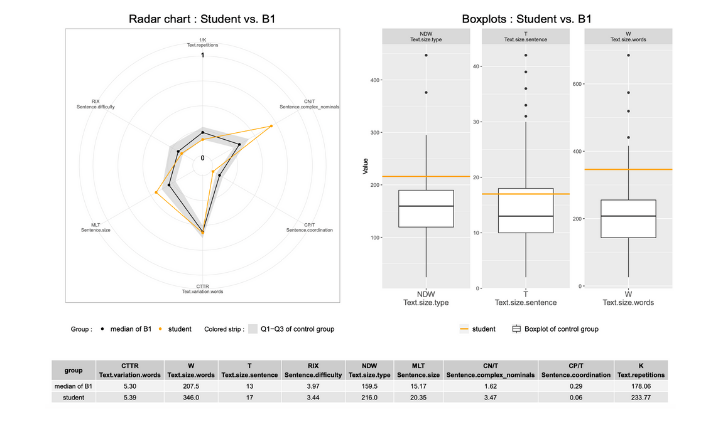
Exemple de graphique radar et boxplot qui constituent les feedbacks d’évaluation du niveau de langue
Ces feedbacks proposent :
– une description des indicateurs présentés aux étudiants. Ces indicateurs (au nombre de 9) ont été choisis comme étant les plus pertinents. Un processus de vulgarisation a été réalisé par l’enseignant afin que les étudiants puissent pleinement s’approprier les résultats.
– un graphique radar et un ensemble de boxplots pour comparaison avec chaque niveau CECRL. Les indicateurs du radar ont été standardisés et les quartiles des indicateurs y sont montrés pour que l’étudiant voie plus l’appartenance à un niveau CECRL comme l’appartenance à un intervalle. Des indicateurs plus classiques (nombre de mots, nombre de phrases, nombre de mots par phrases) et plus concrets sont visualisés par les boxplots. A partir de cette visualisation, l’étudiant peut identifier les points à améliorer afin de passer dans l’intervalle CECRL supérieur.
L’évaluation du dispositif peut se traduire par une étude de l’évolution des indicateurs des étudiants au cours de plusieurs séances de TD, l’intérêt étant de voir si la lecture de ces feedbacks a un impact sur cette évolution, afin de vérifier que les étudiants s’approprient ces retours correctement. Notre objectif est aussi de s’assurer que les indicateurs affichés soient les plus corrélés au niveau CECRL, c’est pourquoi nous étudions aussi un plus grand nombre d’indicateurs dans un objectif d’optimisation du dispositif”³.
Anas Knefati et Antoine Lafontaine travaillent actuellement à une deuxième version du projet sur Python et à une extension du projet actuel sur R. VisLinguistique pourrait également être proposé via une plateforme interactive.
Plus d’informations sur les partenariats de l’ENSAI.
1. DESIR-DUNE, https://desir-dune.univ-rennes.fr/
2. Data Tank, https://desir-dune.univ-rennes.fr/data-tank
3. Présentation du projet VisLinguistique par Anas KNEFATI et Antoine LAFONTAINE